查找(全)
查找
基本概念
- 查找:在数据集合中寻找满足某种条件的数据元素的过程称为查找
- 查找表(查找结构):用于查找的数据集合称为查找表,它由同一类型的数据元素(或记录)组成
- 关键字:数据元素中唯一标识该元素的某个数据项的值,使用基于关键字的查找,查找结果应该是唯一的
查找表的常见操作
- 查找符合条件的数据元素(静态查找表)
- 插入、删除某个元素数据(动态查找表)
查找算法的效率评价
查找长度:在查找运算中,需要对比关键字的次数称为查找长度
平均查找长度(ASL):所有查找过程中进行关键字的比较次数的平均值
P_i$$:查找第i个元素的概率 $$C_i$$:查找第i个元素的查找长度
通常认为查找任何一个元素的概率都相同
评价一个查找算法的效率时,通常考虑查找成功/查找失败两种情况的ASL
线性表的查找
顺序查找
顺序查找,又叫”线性查找“,通常用于线性表
线性表:
- 顺序表
- 链表
算法思想
思想:从头到尾挨个找
算法实现
普通实现:

实现(哨兵)
.png)
算法优化
顺序查找的优化(对有序表)
(被查概率不相等)
将被查概率大的放在靠前的位置
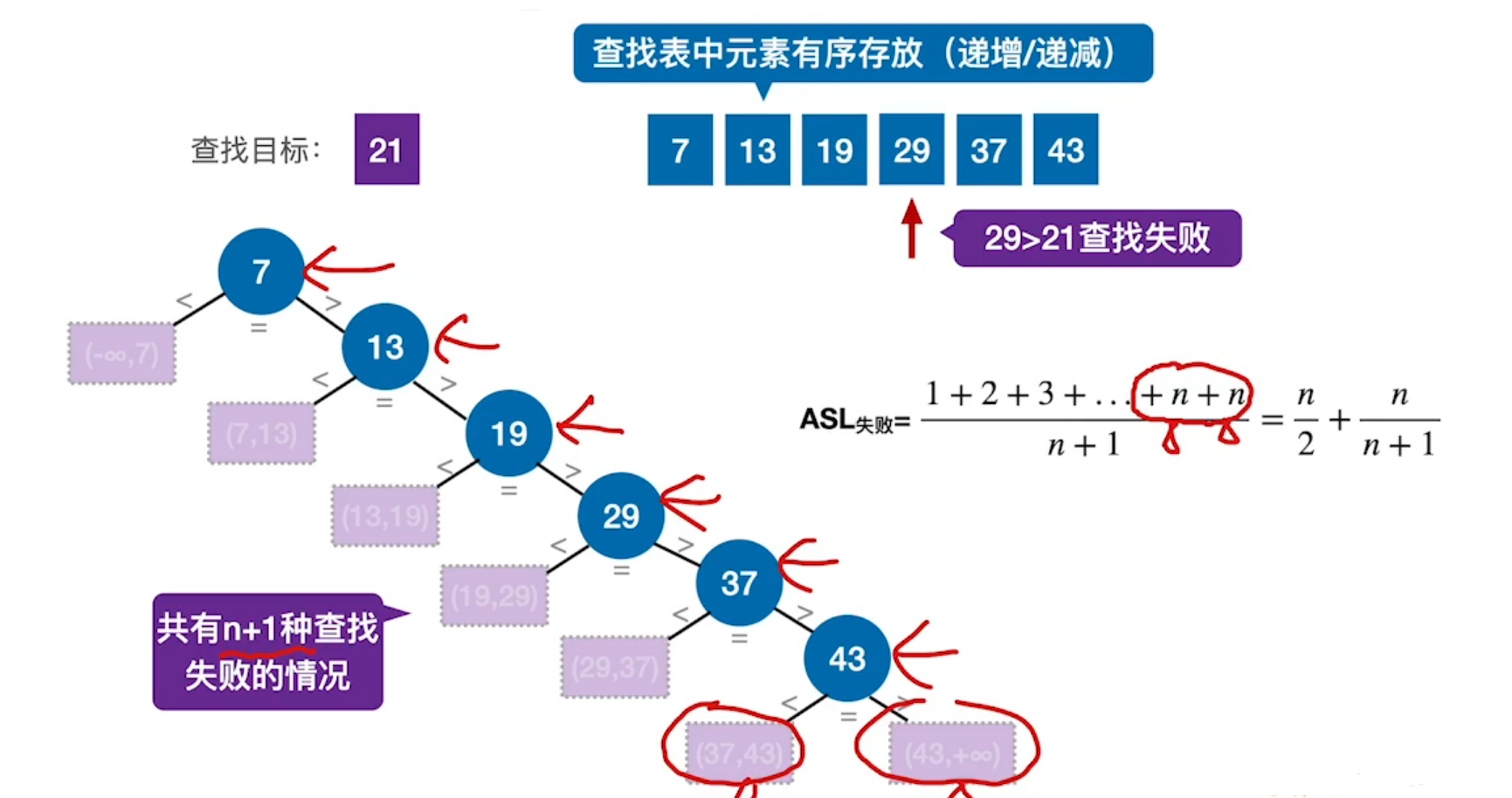
用查找判定树分析ASL
- 一个成功节点的查找长度 = 自身所在层数
- 一个失败节点的查找长度 = 其父节点所在层数
- 默认情况下,各种失败情况或成功情况都等概率发生
折半查找
算法思想
折半查找,又称“二分查找”,仅适用于
算法实现


查找判定树
根据数据构造判定树
根据mid所指的元素与将原有元素分割到左右子树中

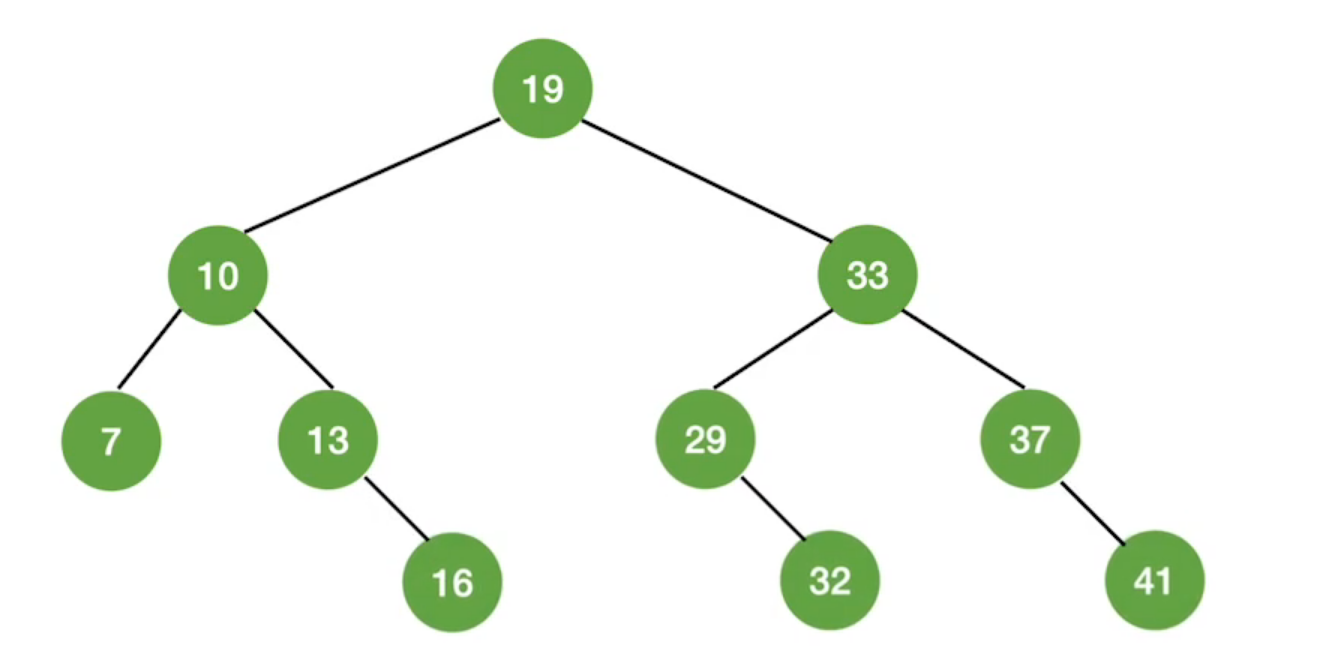
- 如果low和high之间有偶数个元素,则mid分隔后,左半部分比右半部分少一个元素
- 如果当前low和high之间有奇数个元素,则mid分隔后,左右两部分元素个数相等
- 结论:折半查找的判定树中,若$$mid=\lfloor(low+high)/2\rfloor$$,则对于任何一个节点,必有右子树节点数-左子树节点数=0或1——
折半查找的判定树一定是平衡二叉树
折半查找的判定树中,只有最下面一层是不满的,因此,元素个数为n时,树高
判定树节点关键字:左<中<右,满足二叉树排序树的定义
当二叉树的节点有n个时,有失败节点n+1个(等于成功节点的空链域数量)
折半查找效率
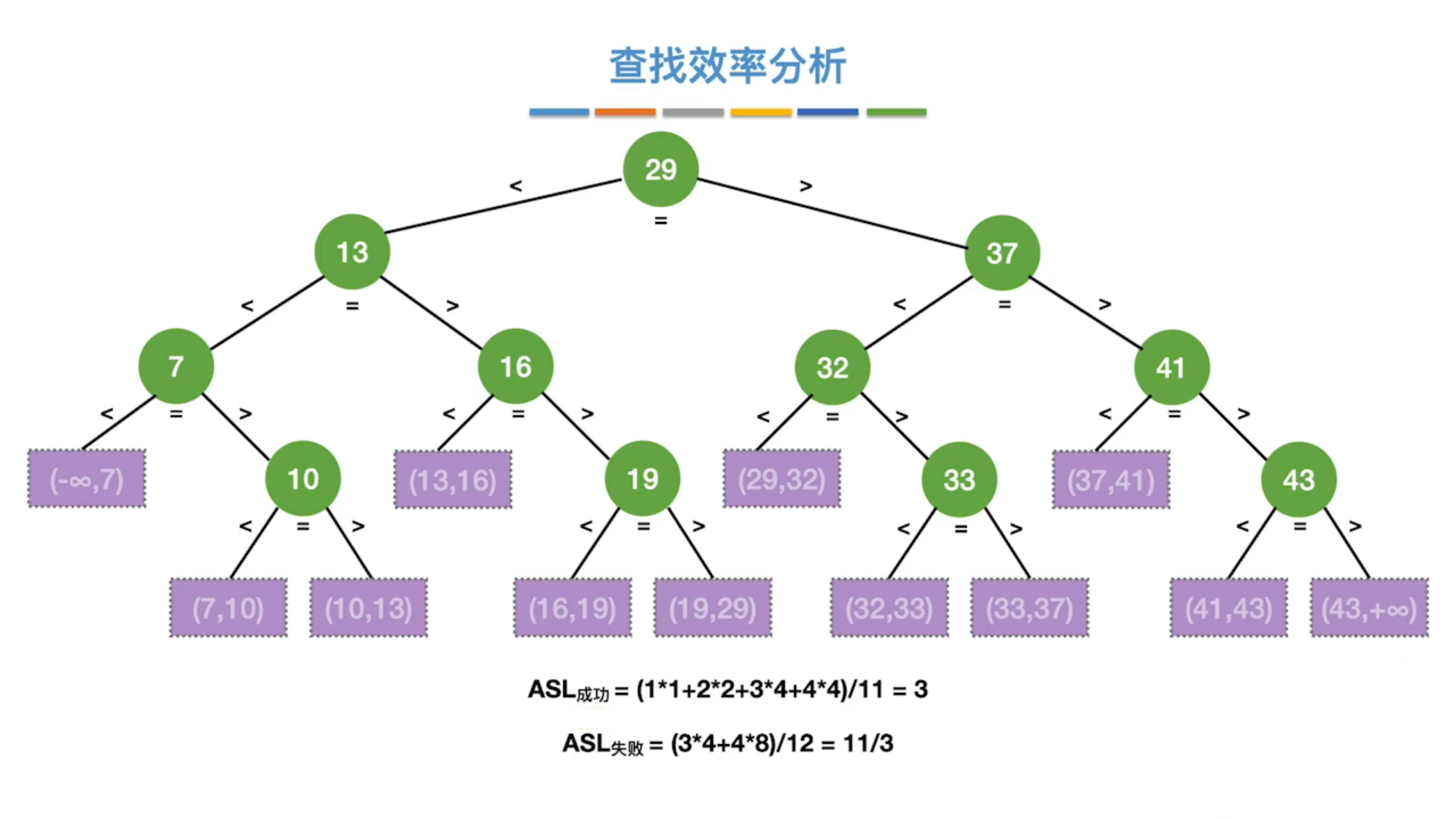
时间复杂度=
问:折半查找时间复杂度=$$O(log_2{n})$$,顺序查找的时间复杂度=$$O(n)$$,那么折半查找的速度一定比顺序查找更快吗?
答:不是,在顺序查找中,当查找的元素是第一个元素时,顺序查找的速度
问:$$mid=\lceil(low+high)/2\rceil$$会出现什么情况?
答:左子树节点数-右子树节点数=0或1
分块查找
分块查找又称为索引顺序查找,是一种性能介于顺序查找和折半查找之间的查找方法。
在此查找方法中,除了本身以外,还需建立“索引表”。
索引表包含两个部分:关键字项(其值为改字表内的最大关键字)和指针项(指示该字表的第一个记录在表中的位置)
特点:块内无序、块间有序、
代码:

过程:
- 在索引表中确定待查记录所属的分块
- 在块内顺序查找
查找效率分析(ASL)
.png)
设索引查找和块内查找的平均查找长度分别为$$L_I$$、$$L_S$$,则分块超找的平均查找长度为
用顺序查找查索引表,则$$L_I=(1+2+...+b)/b=(b+1)/2$$,$$L_S=(1+2+...+s)/s=(s+1)/2$$
当$$s=\sqrt[]n$$时,$$ASL_{最小}=\sqrt[]n+1$$
数表的查找
二叉排序树(BST)
>又称二叉查找树二叉排序树的定义
二叉排序树或者是一棵空树,或者是具有下列性质的二叉树:
- 若它的左子树不空,则左子树上所有节点的的值均小于它的根节点的值;
- 若它的右子树不空,则右子树上所有节点的值均大于它的根节点的值
- 它的左右子树也分别为二叉排序树
左子树节点值<根节点值<右子树节点值
二叉排序树的查找
步骤:
- 若二叉排序树为空,则查找失败,返回空指针
- 若二叉排序树非空,将给定值key与根节点的关键字
T->data.key进行比较- 若key等于
T->data.key,则查找成功,返回根节点的地址 - 若key小于
T->data.key,则递归查找左子树 - 若key大于
T->data.key,则递归查找右子树
- 若key等于
二叉排序树的插入
二叉排序树的创建
二叉排序树的删除
查找效率分析
平衡二叉树
平衡二叉树的定义
平衡二叉树的平衡调整方法
平衡二叉树的插入
散列表的查找
散列表的基本概念
散列表(哈希表),是一种数据结构,特点是:数据元素的与其直接相关
如何建立“关键字”与“存储地址”的联系?
通过“散列函数(哈希函数)”:$$Add=H(key)$$实现
- 散列函数和散列地址:$$p=H(key)$$,$$H$$为散列函数,$$p$$为散列地址
- 散列表:一个连续的地址空间,用以存储按散列函数计算得到相应散列地址的数据记录
- 冲突和同义词:$$key_1\not=key_2$$,$$H(key_1)=H(key_2)$$,这种现象称为冲突,$$key_1$$,$$key_2$$互为同义词
散列函数的构造方法
数字分析法
选取数码分布较为均匀的若干位作为散列地址
设关键字是r进制数(如十进制数),而r个数码在各位上出现的频率不一定相同,可能在某些位上分布均匀一些,每种数码出现的机会均等;而在某些位上分布不均匀,只有某几种数码经常出现,此时可选取数码分布较为均匀的若干位作为散列地址。
这种方法适合于已知的关键字集合,若更换了关键字,则需要重新构造新的散列函数。
平方取中法:取关键字的平方值的中间几位作为散列地址
具体取多少位要视实际情况而定。这种方法得到的散列地址与关键字的每位都有关系,因此使得散列地址分布比较均匀,适用于关键字的每位取值都不够均匀或均小于散列地址所需的位数。
折叠法
将关键字分割成位数相同的几部分,然后取这几部分叠加和作为散列地址。根据数叠加的方式,可以把折叠法分为移位叠加、边界叠加。
key=45387765213$$,表长为1000: 
除留余数法
p$$为不大于表长$$m$$但最接近或等于$$m$$的最大<mark>质数</mark> > 用质数取模,分布更均匀,冲突更少
直接定址法
其中,a和b是常数。这种方法计算最简单,且不会产生冲突。它适合关键字的分布基本连续的情况,若关键字分布不连续,空位较多,则会造成存储空间的浪费。
处理冲突的方法
开放地址法
所谓开放定址法,是指可存放新表项的空闲地址既向它的同义词表项开放,又向它的非同义词表项开放。其数学递推公式为:
m$$为散列表表长;$$d_i$$为增量序列 根据$$d$$的取值不同,可分为以下三种方法: 1. <strong>线性探测法</strong>
d_i=1,2,3,...,m-1
d_i=12,-12,22,-22,32,...,k2,-k^2(k<=m/2)
d_i=伪随机数序列
链地址法(拉链法):把具有相同散列地址的记录放在同一个单链表中,称之为同义词单链表
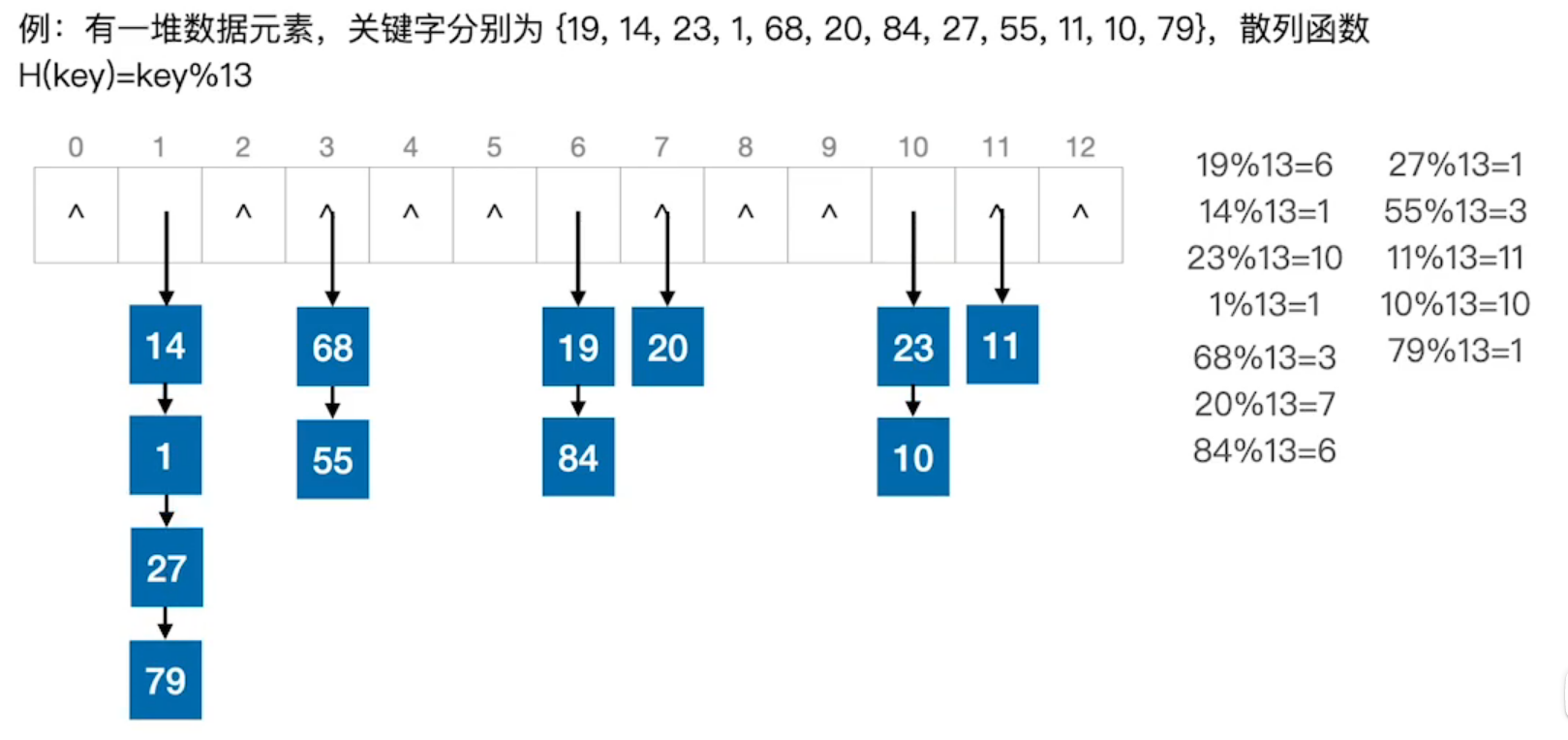
散列表的查找
\alpha$$:装填因子$$=ASL_{失败}
装填因子表示的是散列表装填的满不满,越大,越空;越小,越满。